Design Pattern and Architecture in C++
Design Pattern
- Singleton Pattern
- Factory Design Pattern
- Template Design Pattern
- Observer Design Pattern
- Observer code Example - easier one to refer Link
- Facade Design Pattern
- Command Pattern
- Object Pool design pattern
- Visitor pattern
- Basic Concepts
- OOPS Design Document
- UML Diagram Link
- Design Pattern PPT created by me
- SOLID Principle PPT created by me
- Liskov Substitution principle is an extension of Open Closed Principle
- This principle is there to help you to implement OCP in correct way to ensure that you can change one part of your system without breaking other parts.
- This principle will help you to decide the base class and sub class you have selected in your architecture , are they belonging to same hierarchy or not.
- This principle defines that objects of a superclass shall be replaceable with objects of its subclasses without breaking the application.
- This requires the objects of your subclasses to behave in the same way as the objects of your superclass.
- Liskov Substitution Principle - YouTube
- Smaller components are easier to maintain
- Program can be divided based on functional aspects
- Desired level of abstraction can be brought in the program
- Components with high cohesion can be re-used again
- Concurrent execution can be made possible
- Desired from security aspect


Event-driven communication
Event-driven programming is a very common practice for building distributed network applications. With event-driven programming, it is easier to split complex systems into isolated components that have a limited set of responsibilities and because of that, it is especially popular in service-oriented and microservice architectures. In such architectures, the flow of events happens not between classes or functions living inside of a single computer process, but between many networked services. In large and distributed architectures, the flow of events between services is often coordinated using special communication protocols (for example, AMQP and ZeroMQ) often with the help of dedicated services acting as message brokers. We will discuss some of these solutions later in the Event-driven architectures section.
However, you don’t need to have a formalized way of coordinating events, nor a dedicated event-handling service to consider your networked code as an event-based application. Actually, if you take a more detailed look at a typical Python web application, you’ll notice that most Python web frameworks have many things in common with GUI applications. Let’s, for instance, consider a simple web application that was written using the Flask microframework:
import this from flask import Flask app = Flask(__name__) rot13 = str.maketrans(
"ABCDEFGHIJKLMabcdefghijklmNOPQRSTUVWXYZnopqrstuvwxyz",
"NOPQRSTUVWXYZnopqrstuvwxyzABCDEFGHIJKLMabcdefghijklm"
) def simple_html(body):
return f"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Book Example</title>
</head>
<body>
{body}
</body>
</html>
""" @app.route('/')
def hello():
return simple_html("<a href=/zen>Python Zen</a>") @app.route('/zen')
def zen():
return simple_html(
"<br>".join(this.s.translate(rot13).split("\n"))
) if __name__ == '__main__':
app.run()
- Class Diagram
- Component Diagram
- Deployment Diagram
- Object Diagram
- Package Diagram
- Profile Diagram
- Composite Structure Diagram
- Use Case Diagram
- Activity Diagram
- State Machine Diagram
- Sequence Diagram
- Communication Diagram
- Interaction Overview Diagram
- Timing Diagram
Principles of Software Architecture
Architectural quality attributes:
- Modifiability
- Testability
- Scalability/performance
- Security
- Deployability
Defining Software Architecture
software architecture is a description of the subsystems or components of a software system, and the relationships between them.
"Architecture is the fundamental organization of a system embodied in its components, their relationships to each other, and to the environment, and the principles guiding its design and evolution."
It is possible to get an umpteen number of such definitions of software architecture if one spends some time searching on the Web. The wordings might differ, but all the definitions refer to some core, fundamental aspects underlying software architecture.
Software Architecture versus design
In the experience of the author, this question of the software architecture of a system versus its design seems to pop up quite often, in both online as well as offline forums. Hence, let us take a moment to understand this aspect.
Though both terms sometimes are often used interchangeably, the rough distinction of architecture versus design can be summarized as follows:
Architecture is involved with the higher level of description structures and interactions in a system. It is concerned with those questions that entail decision making about the skeleton of the system, involving not only its functional but also its organizational, technical, business, and quality attributes.
Design is all about the organization of parts or components of the system and the subsystems involved in making the system. The problems here are typically closer to the code or modules in question, such as these:
- What modules to split code into? How to organize them?
- Which classes (or modules) to assign the different functionalities to?
- Which design pattern should I use for class "C"?
- How do my objects interact at runtime? What are the messages passed, and how to organize the interaction?
software architecture is about the design of the entire system, whereas, software design is mostly about the details, typically at the implementation level of the various subsystems and components that make up those subsystems.
In other words, the word design comes up in both contexts, however, with the distinction that the former is at a much higher abstraction and at a larger scope than the latter.
There is a rich body of knowledge available for both software architecture and design, namely, architectural patterns and design patterns respectively. We will discuss both these topics in later chapters of this book.
In both the formal IEEE definition and the rather informal definition given earlier, we find some common, recurring themes. It is important to understand them in order to take our discussion on software architecture further:
System: A system is a collection of components organized in specific ways to achieve a specific functionality. A software system is a collection of such software components. A system can often be subgrouped into subsystems.
Structure: A structure is a set of elements that are grouped or organized together according to a guiding rule or principle. The elements can be software or hardware systems. A software architecture can exhibit various levels of structures depending on the observer's context.
Environment: The context or circumstances in which a software system is built, which has a direct influence on its architecture. Such contexts can be technical, business, professional, operational, and so on.
Stakeholder: Anyone, a person or groups of persons, who has an interest or concern in the system and its success. Examples of stakeholders are the architect, development team, customer, project manager, marketing team, and others.
Now that you have understood some of the core aspects of software architecture, let us briefly list some of its characteristics.
All software architectures exhibit a common set of characteristics. Let us look at some of the most important ones here.
An architecture of a system is best represented as structural details of the system. It is a common practice for practitioners to draw the system architecture as a structural component or class diagram in order to represent the relationships between the subsystems.
For example, the following architecture diagram describes the backend of an application that reads from a tiered database system, which is loaded using an ETL process:
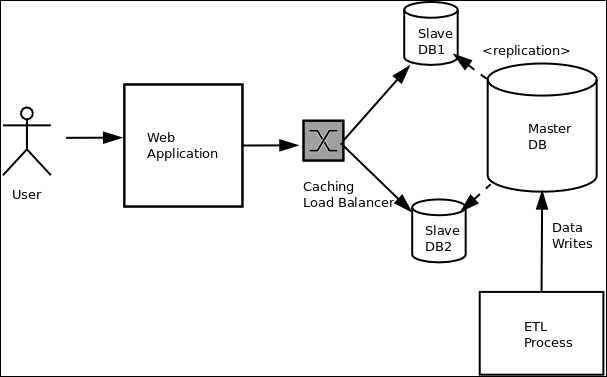
Example Architecture diagram showing system structure
Structures provide insight into architectures, and provide a unique perspective to analyze the architecture with respect to its quality attributes.
Some examples are as follows:
The runtime structures, in terms of the objects created at runtime, and how they interact often determine the deployment architecture. The deployment architecture is strongly connected to the quality attributes of scalability, performance, security, and interoperability.
The module structures, in terms of how the code is broken down and organized into modules and packages for task breakdown, often has a direct bearing on the maintainability and modifiability (extensibility) of a system. This is explained as follows:
Code which is organized with a view to extensibility would often keep the parent classes in separate well-defined packages with proper documentation and configuration, which are then easily extensible by external modules, without the need to resolve too many dependencies.
Code which is dependent on external or third-party developers (libraries, frameworks, and the like) would often provide setup or deployment steps, which manually or automatically pull in these dependencies from external sources. Such code would also provide documentation (README, INSTALL, and so on) which clearly document these steps.
A well-defined architecture clearly captures only the core set of structural elements required to build the core functionality of the system, and which have a lasting effect on the system. It does not set out to document everything about every component of the system.
For example, an architect describing the architecture of a user interacting with a web server for browsing web pages—a typical client/server architecture—would focus mainly on two components: the user's browser (client) and the remote web server (server), which form the core elements of the system.
The system may have other components such as multiple caching proxies in the path from the server to the client, or a remote cache on the server which speeds up web page delivery. However, this is not the focus of the architecture description.
This is a corollary to the characteristics described previously. The decisions that help an architect to focus on some core elements of the system (and their interactions) are a result of the early design decisions about a system. Thus, these decisions play a major role in further development of the system due to their initial weight.
For example, an architect may make the following early design decisions after careful analysis of the requirements for a system:
The system will be deployed only on Linux 64-bit servers, since this satisfies the client requirement and performance constraints
The system will use HTTP as the protocol for implementing backend APIs
The system will try to use HTTPS for APIs that transfer sensitive data from the backend to frontend using encryption certificates of 2,048 bits or higher
The programming language for the system would be Python for the backend, and Python or Ruby for the frontend
Note
The first decision freezes the deployment choices of the system to a large extent to a specific OS and system architecture. The next two decisions have a lot of weight in implementing the backend APIs. The last decision freezes the programming language choices for the system.
Early design decisions need to be arrived at after careful analysis of the requirements and matching them with the constraints – such as organizational, technical, people, and time constraints.
A system is designed and built, ultimately, at the behest of its stakeholders. However, it is not possible to address each stakeholder requirement to its fullest due to an often contradictory nature of such requirements. Following are some examples:
The marketing team is concerned with having a full-featured software application, whereas, the developer team is concerned with feature creep and performance issues when adding a lot of features.
The system architect is concerned with using the latest technology to scale out his deployments to the cloud, while the project manager is concerned about the impact such technology deployments will have on his budget. The end user is concerned about correct functionality, performance, security, usability, and reliability, while the development organization (architect, development team, and managers) is concerned with delivering all these qualities while keeping the project on schedule and within budget.
A good architecture tries its best to balance out these requirements by making trade-offs, and delivering a system with good quality attributes while keeping the people and resource costs under limits.
An architecture also provides a common language among the stakeholders, which allows them to communicate efficiently via expressing these constraints, and helping the architect zero-in towards an architecture that best captures these requirements and their trade-offs.
The system structures an architecture describes quite often have a direct mapping to the structure of the teams that build those systems.
For example, an architecture may have a data access layer which describes a set of services that read and write large sets of data—it is natural that such a system gets functionally assigned to the database team, which already has the required skill sets.
Since the architecture of a system is its best description of the top-down structures, it is also often used as the basis for the task-breakdown structures. Thus, software architecture has often a direct bearing on the organizational structures that build it:
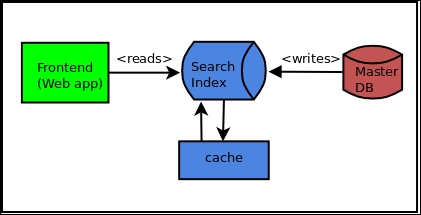
System architecture for a search web application
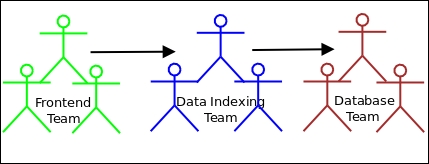
The following diagram shows the mapping to the team structure which would be building this application:
An environment imposes outside constraints or limits within which an architecture must function. In the literature, these are often called architecture in context [Ref: Bass, Kazman]. Some examples are as follows:
Quality attribute requirements: In modern day web applications, it is very common to specify the scalability and availability requirements of the application as an early technical constraint, and capture it in the architecture. This is an example of a technical context from a business perspective.
Standards conformance: In some organizations where there is often a large set of governing standards for software, especially those in the banking, insurance, and health-care domains, these get added to the early constraints of the architecture. This is an example of an external technical context.
Organizational constraints: It is common to see that organizations which either have an experience with a certain architectural style or a set of teams operating with certain programming environments which impose such a style (J2EE is a good example), prefer to adopt similar architectures for future projects as a way to reduce costs and ensure productivity due to current investments in such architectures and related skills. This is an example of an internal business context.
Professional context: An architect's set of choices for a system's architecture, aside from these outside contexts, is mostly shaped from his set of unique experiences. It is common for an architect to continue using a set of architectural choices that he has had the most success with in his past for new projects.
Architecture choices also arise from one's own education and professional training, and also from the influence of one's professional peers.
Every system has an architecture, whether it is officially documented or not. However, properly documented architectures can function as an effective documentation for the system. Since an architecture captures the system's initial requirements, constraints, and stakeholder trade-offs, it is a good practice to document it properly. The documentation can be used as a basis for training later on. It also helps in continued stakeholder communication, and for subsequent iterations on the architecture based on changing requirements.
The simplest way to document an architecture is to create diagrams for the different aspects of the system and organizational architecture such as Component Architecture, Deployment Architecture, Communication Architecture, and the Team or Enterprise Architecture.
Other data that can be captured early include the system requirements, constraints, early design decisions, and rationale for those decisions.
Most architectures conform to certain set of styles which have had a lot of success in practice. These are referred to as architectural patterns. Examples of such patterns are Client-Server, Pipes and Filters, Data-based architectures, and others. When an architect chooses an existing pattern, he gets to refer to and reuse a lot of existing use cases and examples related to such patterns. In modern day architectures, the job of the architect comes down to mixing and matching existing sets of such readily available patterns to solve the problem at hand.
For example, the following diagram shows an example of a client-server architecture:
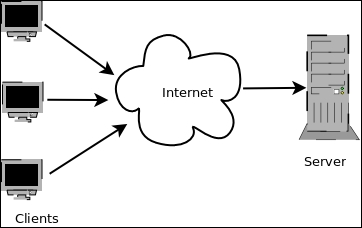
Example of Client-Server Architecture
And the following diagram describes another common architecture pattern, namely, the Pipes and Filters architecture for processing streams of data:

Example of Pipe and Filters Architecture
We will see examples of architectural patterns later in this book.
Patterns
A pattern provides a description of the solution to a recurring design problem of some specific domain in such a way that the solution can be used again and again. The objective of each pattern is to provide an insight to a designer who can determine the following.
- Whether the pattern can be reused
- Whether the pattern is applicable to the current project
- Whether the pattern can be used to develop a similar but functionally or structurally different design pattern.
Types of Design Patterns
Software engineer can use the design pattern during the entire software design process. When the analysis model is developed, the designer can examine the problem description at different levels of abstraction to determine whether it complies with one or more of the following types of design patterns.
- Architectural patterns: These patterns are high-level strategies that refer to the overall structure and organization of a software system. That is, they define the elements of a software system such as subsystems, components, classes, etc. In addition, they also indicate the relationship between the elements along with the rules and guidelines for specifying these relationships. Note that architectural patterns are often considered equivalent to software architecture.
- Design patterns: These patterns are medium-level strategies that are used to solve design problems. They provide a means for the refinement of the elements (as defined by architectural pattern) of a software system or the relationship among them. Specific design elements such as relationship among components or mechanisms that affect component-to-component interaction are addressed by design patterns. Note that design patterns are often considered equivalent to software components.
- Idioms: These patterns are low-level patterns, which are programming-language specific. They describe the implementation of a software component, the method used for interaction among software components, etc., in a specific programming language. Note that idioms are often termed as coding patterns.
Modularity
Modularity is achieved by dividing the software into uniquely named and addressable components, which are also known as modules. A complex system (large program) is partitioned into a set of discrete modules in such a way that each module can be developed independent of other modules. After developing the modules, they are integrated together to meet the software requirements. Note that larger the number of modules a system is divided into, greater will be the effort required to integrate the modules.

Modularizing a design helps to plan the development in a more effective manner, accommodate changes easily, conduct testing and debugging effectively and efficiently, and conduct maintenance work without adversely affecting the functioning of the software.
Information Hiding
Modules should be specified and designed in such a way that the data structures and processing details of one module are not accessible to other modules. They pass only that much information to each other, which is required to accomplish the software functions. The way of hiding unnecessary details is referred to as information hiding. IEEE defines information hiding as ‘the technique of encapsulating software design decisions in modules in such a way that the module’s interfaces reveal as little as possible about the module’s inner workings; thus each module is a ‘black box’ to the other modules in the system.

Information hiding is of immense use when modifications are required during the testing and maintenance phase. Some of the advantages associated with information hiding are listed below.
- Leads to low coupling
- Emphasizes communication through controlled interfaces
- Decreases the probability of adverse effects
- Restricts the effects of changes in one component on others
- Results in higher quality software.
Refactoring
Refactoring is an important design activity that reduces the complexity of module design keeping its behavior or function unchanged. Refactoring can be defined as a process of modifying a software system to improve the internal structure of design without changing its external behavior. During the refactoring process, the existing design is checked for any type of flaws like redundancy, poorly constructed algorithms and data structures, etc., in order to improve the design. For example, a design model might yield a component which exhibits low cohesion (like a component performs four functions that have a limited relationship with one another). Software designers may decide to refactor the component into four different components, each exhibiting high cohesion. This leads to easier integration, testing, and maintenance of the software components.
Stepwise Refinement
Stepwise refinement is a top-down design strategy used for decomposing a system from a high level of abstraction into a more detailed level (lower level) of abstraction. At the highest level of abstraction, function or information is defined conceptually without providing any information about the internal workings of the function or internal structure of the data. As we proceed towards the lower levels of abstraction, more and more details are available.
Software designers start the stepwise refinement process by creating a sequence of compositions for the system being designed. Each composition is more detailed than the previous one and contains more components and interactions. The earlier compositions represent the significant interactions within the system, while the later compositions show in detail how these interactions are achieved.
Concurrency
Computer has limited resources and they must be utilized efficiently as much as possible. To utilize these resources efficiently, multiple tasks must be executed concurrently. This requirement makes concurrency one of the major concepts of software design. Every system must be designed to allow multiple processes to execute concurrently, whenever possible. For example, if the current process is waiting for some event to occur, the system must execute some other process in the mean time.
However, concurrent execution of multiple processes sometimes may result in undesirable situations such as an inconsistent state, deadlock, etc. For example, consider two processes A and B and a data item Q1 with the value ‘200’. Further, suppose A and B are being executed concurrently and firstly A reads the value of Q1 (which is ‘200’) to add ‘100’ to it. However, before A updates es the value of Q1, B reads the value ofQ1 (which is still ‘200’) to add ’50’ to it. In this situation, whether A or B first updates the value of Q1, the value of would definitely be wrong resulting in an inconsistent state of the system. This is because the actions of A and B are not synchronized with each other. Thus, the system must control the concurrent execution and synchronize the actions of concurrent processes.
Developing a Design Model
To develop a complete specification of design (design model), four design models are needed. These models are listed below.
- Data design: This specifies the data structures for implementing the software by converting data objects and their relationships identified during the analysis phase. Various studies suggest that design engineering should begin with data design, since this design lays the foundation for all other design models.
- Architectural design: This specifies the relationship between the structural elements of the software, design patterns, architectural styles, and the factors affecting the ways in which architecture can be implemented.
- Component-level design: This provides the detailed description of how structural elements of software will actually be implemented.
- Interface design: This depicts how the software communicates with the system that interoperates with it and with the end-users.

SOLID principles
This is a question which I was asked in a senior software engineer position for a Berlin based company.
SOLID is a set of 5 principles, which is followed to make maintainable systems.
S — Single Responsible Principle
O — Open-Closed Principle
L — Liskov Substitution Principle
I — Interface Segregation Principle
D-Dependency Inversion Principle
Single Responsibility Principle(SRP)
A class should have one and only one responsibility. And it should only have one reason to change.
The goal of SRP is to limit the impact of change. If a class has only one responsibility, there will only a few self contained cases to test. When there is a change, the impact will be less(minimal changes in a very few places).
If a class has less functionalities, there will be less coupling with other classes. Only a few client classes will depend on it. So, there will be high cohesion.
Finally, it will be easy to search in codebase, because class name is monolitic.
It’s a sign of trouble if a class does tons of things, if things don’t break now, it will break someday.
In c++ standard template library, std::vector only implements the bare minimum functions, like methods to insert, delete, clear elements, methods to resize, query the size, check emptyness, elements at an index. To be useful with stl algorithims, it provides iterators. By following SRP, std::vector is just stable and self sufficient class.
Open-Closed Principle(OCP)
Classes(or software entities) should be open for extension, but closed for modificationclasses should be open for extension, but closed for modification.
When a class doesn’t change, the client code using those will not change. The test cases doesn’t change. But when you want to add features to a class, you should extend the existing class.
Many modern object oriented concepts enforce it. An interface (or an abstract class in C++) leave a few methods unimplemented. Child class can implement it to add new features.
Similarly a function can take another function as an argument to provide extensibility. Many find variant algorithims in stl take a function argument to enforce open-closed principle.
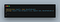

Here, any container which provides begin() and end() iterator can fully take advantage of the function. UnaryPredicate provides the extensibility. So find_if() is closed for the search algorithim modification, but open for search creteria extension.
Liskov Substitution Principle(LSP)
Subtype must be a substitute for it’s base type.
When a class is inherited from a base class, then the subclass can replace for that base class.If it doesn’t work, it means there is some issue in the inheritance design.
A class should inherit another class if it needs all the functionalies. Otherwise the inherited functionalities will not make sense. If the inheritance doesn’t work, the developer should use delegation model.
Let’s say we have a Car base class and a couple of child classes. All cars can be fueled up.
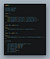

Now we add Tesla.
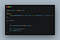
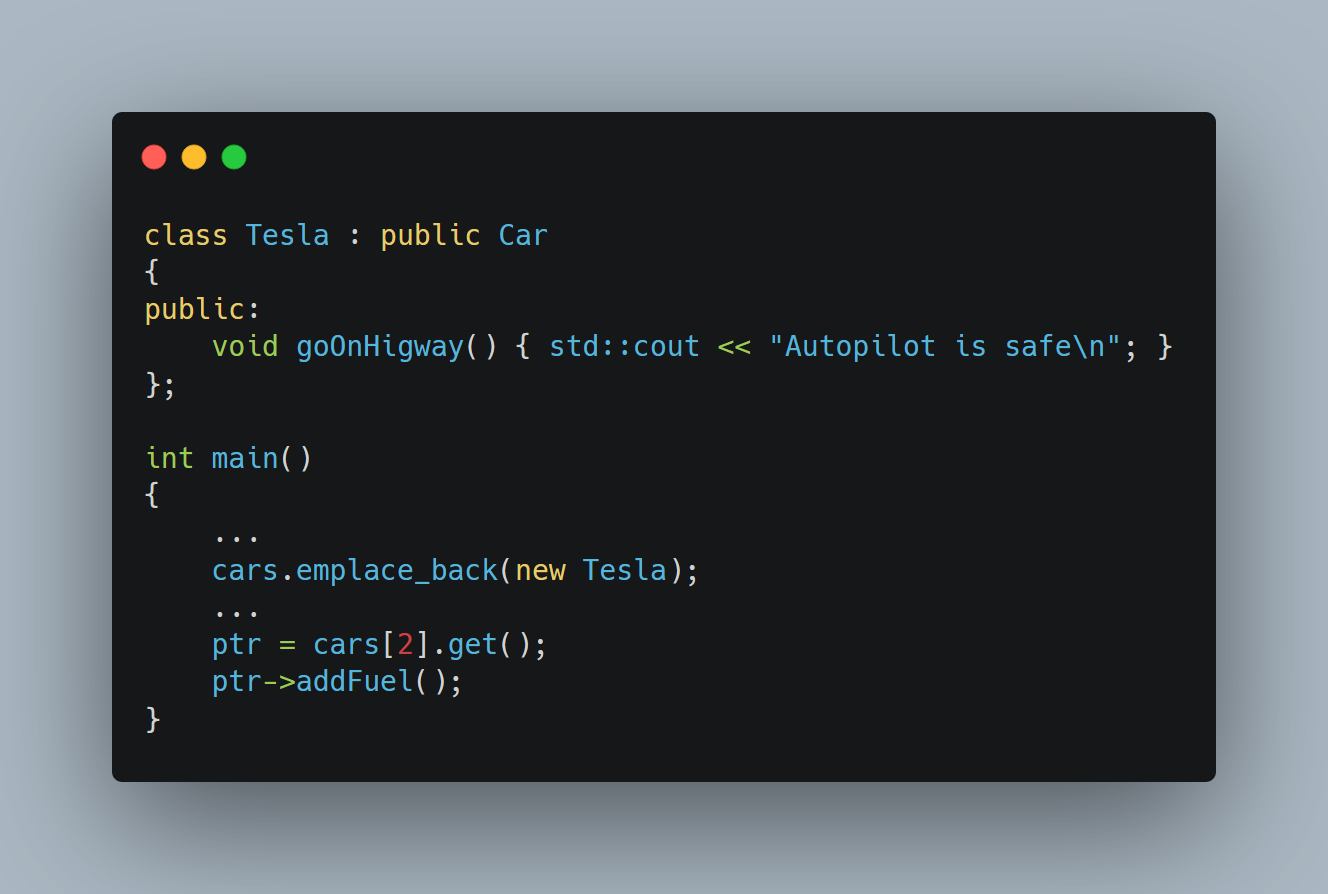
Now it caused a lot of problem. You can’t put fuel in Tesla. It simply doesn’t make any sense.
You can remove addFuel() from Cars class and model it as a separate behavior.
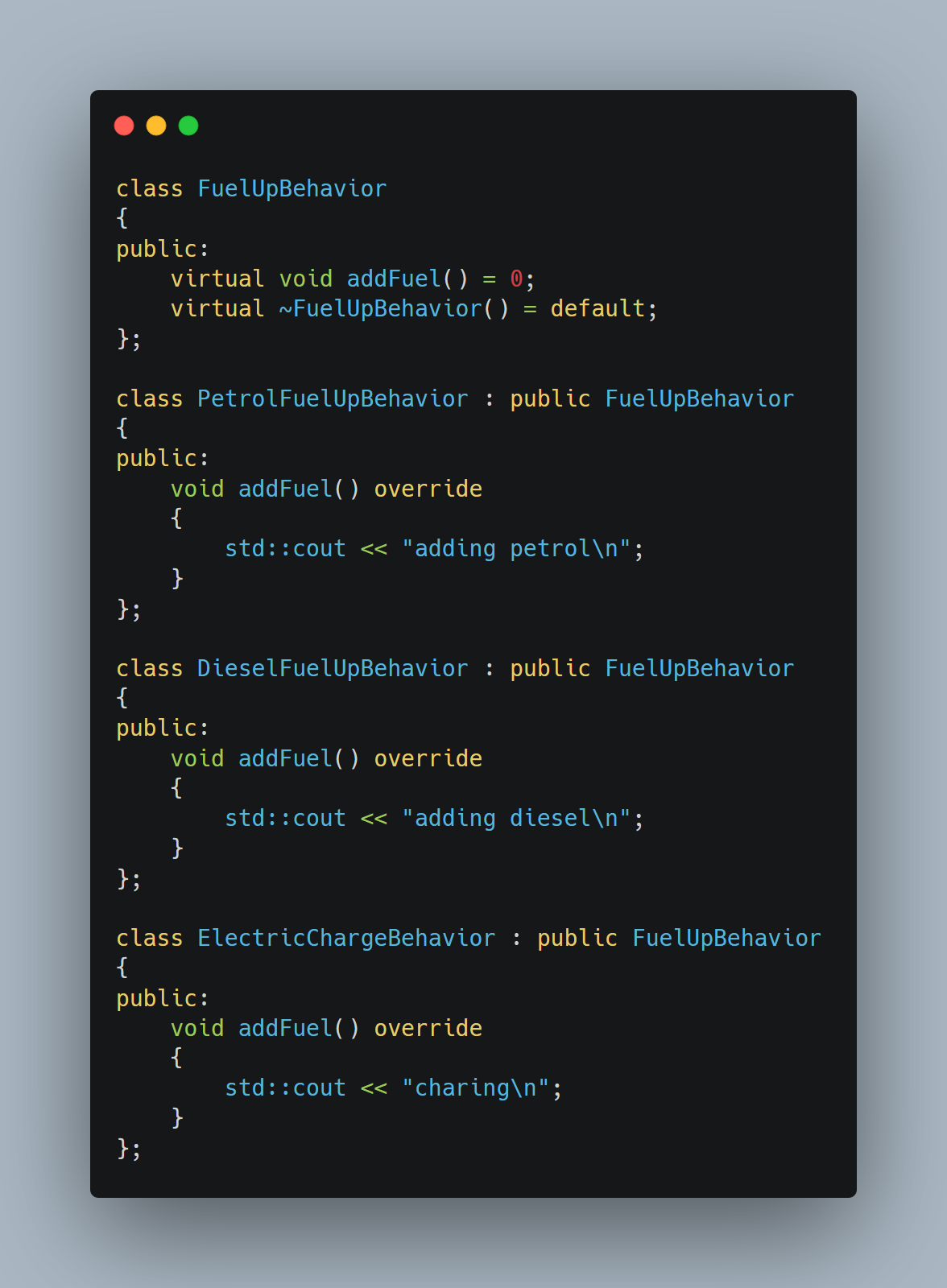
Now, we create a member variable in Car, set the behavior during construction.


In this we don’t mess up the inheritance, and our design is still flexible to support more classes.
Interface Segregation Principle(ISP)
Clients should not be forced to depend upon interfaces that they do not use.
Like SRP, ISP tries to minimize the impact of changes. When a client doesn’t need to use an interface, it should not depend on it.
If an interface changes, only the client who uses it, should be modified. In many languages, it also reduces the build time, because dependency is created if it’s necessary.
Dependency Inversion Principle(DIP)
Dependency Inversion refers to the decoupling of software modules. This way, instead of high-level modules depending on low-level modules, both will depend on abstractions.
In a complex software, changes are constant and usually at the implementetation layer. Everytime there is a change in the implementation, if the interface doesn’t change, it’s not necessary to change the clients. That’s why different modules should depend on the interface, not on the implementation.
In languages like C++, DIP saves a lot of build time. And also, if only the implementation changes, only the libraries are updated.
SOLID design principles for the modern C++
This is a series of entries explaining the fundamental principles of object-oriented programming to the modern C++ development. How to design classes? How to design objects? How to design relationships between classes and objects?
Why do we need a design? It is because the only consistent thing about a software is that it is always changing. Many times, clients do not know their requirements. Technology also change, and it changes a lot. It is always going to change. So designers and developers have to accommodate future changes while they are creating the present day software.
 Photo from Unsplash
Photo from Unsplash
All these design philosophies are based on three things:
- DRY - Do not repeat yourself. It is one of the most important things. It is based on the knowledge that software is constantly changing. For example, imagine that a piece of code is duplicated across five different classes, five different functions. And now, that code needs to be changed. Where will it be modified? It will then be modified at five different places where the code was duplicated. However, if that similar piece of code was extracted into a single and reusable component, it will only be modified at a single place only.
- Divide and Conquer - Whenever the file size of the code gets bigger and bigger, think about the concept of divide and conquer. It is influenced by the philosophy that the software will constantly change. There will be an additional code, added functionality, remove some code, and again add something new to the existing code base.
- Expect Change
Accordingly, the designer or the developer will have the coding habits, design habits with the above philosophy in mind. The code will have to accomodate change without destroying the existing working functionality.
On that note, let us discuss some guidelines known as the SOLID principles for OOP.
SOLID principles are the design principles that enable us to manage most of the software design problems. It is an acronym for five design principles intended to make software designs more understandable, flexible and maintainable. Another benefit of SOLID principle is that it will make the code easier to read and understand, thus spending less time figuring out what it does and spend more time actually developing the solution. The principles are a part of the many principles promoted by Robert Martin and named by Michael Feathers.
Single responsibility principle
Sounds easy but the thing with defining a class is the tendency of most developers to add a lot of functionalities inside it. A good question to always remember when designing is, “What is the main responsibility of your class/component/microservice?” A class should have one, and only one reason to change.
Open for extension, closed for modification
Having a good understanding of SRP, a class can basically be defined with an intentional knowledge of its role, however, there can be instances to perform modifications to it. An extension is fine, but altering the design of the class would not conform to OCP.
Liskov substitution principle
The principle suggests that objects of a base class can be substituted with objects of its derived classes without breaking the application. This means that the objects of derived classes behave in a way similar to the base class.
Interface segregation principle
The ability to separate into much smaller interfaces from a bigger interface is the main characteristic of ISP. It splits the interface, sometimes packed with diverse methods, into separate interfaces.
Dependency inversion principle
Both the high-level and low-level modules depend on abstractions, and not from each other. This results in the inversion thinking that low-level modules should depend on high-level etc.
 Photo from Unsplash
Photo from Unsplash
Importance of following SOLID design principles.
- Decoupling of the code from other modules or applications. It helps reduce complexity of code.
- When code gets decoupled, implementing of new requirements or bug fixes are fast and timely.
- The code becomes testable.
- The code becomes modular and reusable.
- It decreases side-effects of new implementation or bug fixes.
- It helps increase readability, extensibility and maintenance.
Takeaway initiative
“We must all suffer from one of two pains: the pain of discipline or the pain of regret. The difference is discipline weighs ounces while regret weighs tons. - Jim Rohn”
From STUPID to SOLID Code!
Clermont-Fd Area, France
Jump to: TL;DR
Last week I gave a talk about Object-Oriented Programming at Michelin, the company I am working for. I talked about writing better code, from STUPID to SOLID code! STUPID as well as SOLID are two acronyms, and have been covered quite a lot for a long time. However, these mnemonics are not always well-known, so it is worth spreading the word.
In the following, I will introduce both STUPID and SOLID principles. Keep in mind that these are principles, not laws. However, considering them as laws would be good for those who want to improve themselves.
STUPID code, seriously?¶
This may hurt your feelings, but you have probably written STUPID code already. I have too. But, what does that mean?
In the following, I will explain the individual points with more details. This is more or less the transcript of my talk.
Singleton¶
The Singleton pattern is probably the most well-known design pattern, but also the most misunderstood one. Are you aware of the Singleton syndrome? It is when you think the Singleton pattern is the most appropriate pattern for the current use case you have. In other words, you use it everywhere. That is definitely not cool.
Singletons are controversial, and they are often considered anti-patterns. You should avoid them. Actually, the use of a singleton is not the problem, but the symptom of a problem. Here are two reasons why:
- Programs using global state are very difficult to test;
- Programs that rely on global state hide their dependencies.
But should you really avoid them all the time? I would say yes because you can often replace the use of a singleton by something better. Avoiding static things is important to avoid something called tight coupling.
Tight Coupling¶
Tight coupling, also known as strong coupling, is a generalization of the Singleton issue. Basically, you should reduce coupling between your modules. Coupling is the degree to which each program module relies on each one of the other modules.
If making a change in one module in your application requires you to change another module, then coupling exists. For instance, you instantiate objects in your constructor’s class instead of passing instances as arguments. That is bad because it doesn’t allow further changes such as replacing the instance by an instance of a sub-class, a mock or whatever.
Tightly coupled modules are difficult to reuse, and also hard to test.
Untestability¶
In my opinion, testing should not be hard! No, really. Whenever you don’t write unit tests because you don’t have time, the real issue is that your code is bad, but that is another story.
Most of the time, untestability is caused by tight coupling.
Premature Optimization¶
Donald Knuth said: “premature optimization is the root of all evil. There is only cost, and no benefit”. Actually, optimized systems are much more complex than just rewriting a loop or using pre-increment instead of post-increment. You will just end up with unreadable code. That is why Premature Optimization is often considered an anti-pattern.
A friend of mine often says that there are two rules to optimize an application:
- don’t do it;
- (for experts only!) don’t do it yet.
Indescriptive Naming¶
This should be obvious, but still needs to be said: name your classes, methods, attributes, and variables properly. Oh, and don’t abbreviate! You write code for people, not for computers. They don’t understand what you write anyway. Computers just understand 0 and 1. Programming languages are for humans.
Duplication¶
Duplicated code is bad, so please Don’t Repeat Yourself (DRY), and also Keep It Simple, Stupid. Be lazy the right way - write code only once!
Now that I have explained what STUPID code is, you may think that your code is STUPID. It does not matter (yet). Don’t feel bad, keep calm and be awesome by writing SOLID code instead!
Good collection, keep on doing this
ReplyDelete/*
ReplyDeleteSingletone design pattern provides global access.
singleton provides a way to access the latest values of the class.
*/
#include
#include
#include
using namespace std;
class Singleton
{
private:
static Singleton *Inst;
static std::mutex mu;
public:
static Singleton *getInstance();
Singleton(const Singleton &obj) = delete;
Singleton &operator = (const Singleton &obj) = delete;
void display()
{
cout<<"display function is called"<lck(mu);
if (Inst == NULL)
{
Inst = new Singleton();
}
}
else
{
cout<<"Singleton class is already instantiated";
}
return Inst;
}
void func1()
{
cout<<"First thread is called"<display();
}
}
void func2()
{
cout<<"Second thread is called"<display();
}
}
int main()
{
std::thread thread1(func1);
std::thread thread2(func2);
if (thread1.joinable())
{
thread1.join();
}
if (thread2.joinable())
{
thread2.join();
}
return 0;
}
https://www.knowledgehut.com/interview-questions/microservices
ReplyDeletehttps://gist.github.com/devops-school/12ad7130c35b910eda38271380bbe186
ReplyDelete