Microservices based Architecture
1. Revise Kubernetes from the link
Microservices, also known as Microservices Architecture, is basically an SDLC approach in which large applications are built as a collection of small functional modules.
It is one of the most widely adopted architectural concepts within software development.
In addition to helping in easy maintenance, this architecture also makes development faster. Additionally, microservices are also a big asset for the latest methods of software development such as DevOps and Agile.
Furthermore, it helps deliver large, complex applications promptly, frequently, and reliably. Applications are modeled as collections of services, which are:
- Maintainable and testable
- Loosely coupled
- Independently deployable
- Designed or organized around business capabilities
- Managed by a small team
- Self-contained, and independent deployment module.
- Independently managed services.
- In order to improve performance, the demand service can be deployed on multiple servers.
- It is easier to test and has fewer dependencies.
- A greater degree of scalability and agility.
- Simplicity in debugging & maintenance.
- Better communication between developers and business users.
- Development teams of a smaller size.
- Due to the complexity of the architecture, testing and monitoring are more difficult.
- Lacks the proper corporate culture for it to work.
- Pre-planning is essential.
- Complex development.
- Requires a cultural shift.
- Expensive compared to monoliths.
- Security implications.
- Maintaining the network is more difficult.
- Require heavy infrastructure setup.
- Need Heavy investment.
- Require excessive planning to handle or manage operations overhead.
- Microservices are always interdependent. Therefore, they must communicate with each other.
- It is a heavily involved model because it is a distributed system.
- You need to be prepared for operations overhead if you are using Microservice architecture.
- To support heterogeneously distributed microservices, you need skilled professionals.
- It is difficult to automate because of the number of smaller components. For that reason, each component must be built, deployed, and monitored separately.
- It is difficult to manage configurations across different environments for all components.
- Challenges associated with deployment, debugging, and testing.
- HTTP/REST with JSON or binary protocol for request-response
- Websockets for streaming.
- A broker or server program that uses advanced routing algorithms.
- RabbitMQ, Nats, Kafka, etc., can be used as message brokers; each is built to handle a particular message semantic. You can also use Backend as a Service like Space Cloud to automate your entire backend.
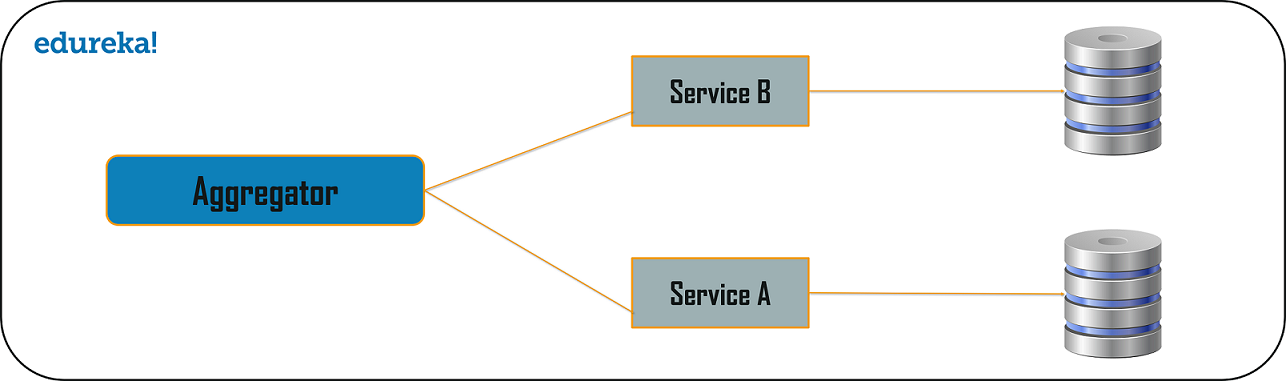
- Aggregator
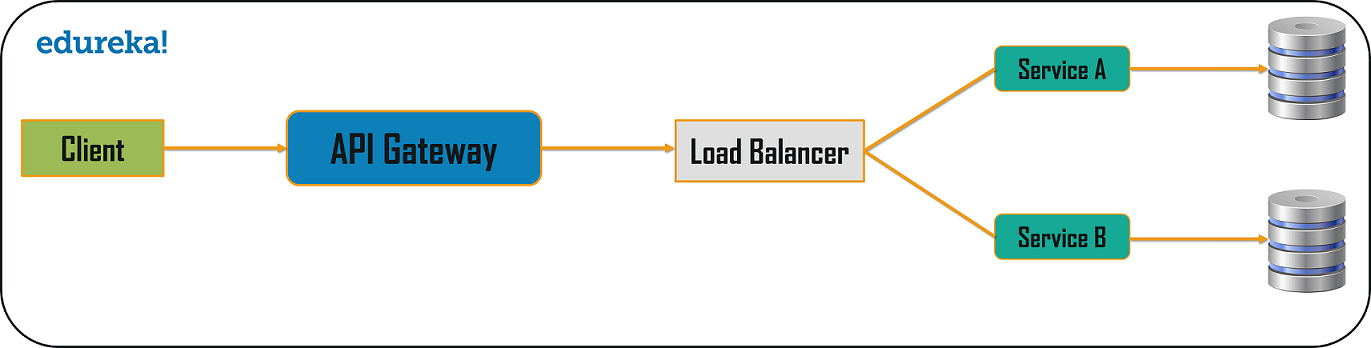
- API Gateway
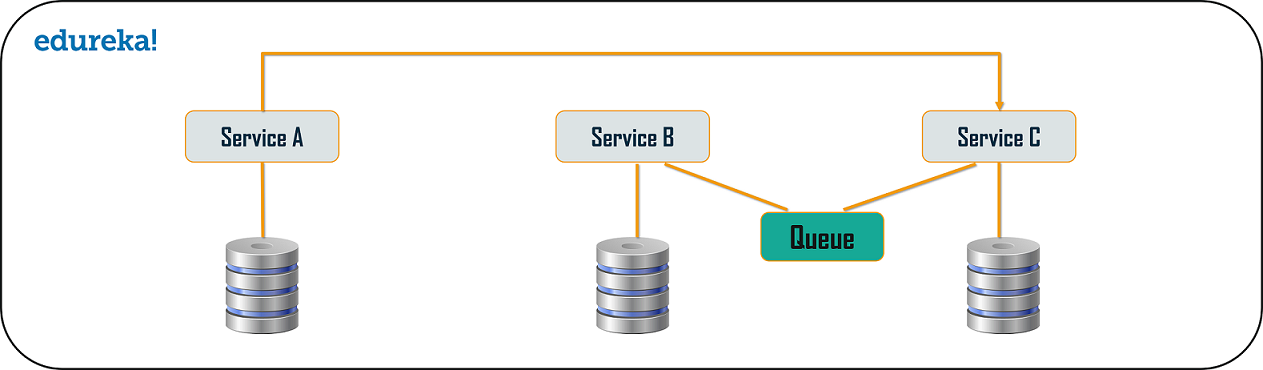
- Chained or Chain of Responsibility
- Asynchronous Messaging
- Database or Shared Data
- Event Sourcing
- Branch
- Command Query Responsibility Segregator
- Circuit Breaker
- Decomposition
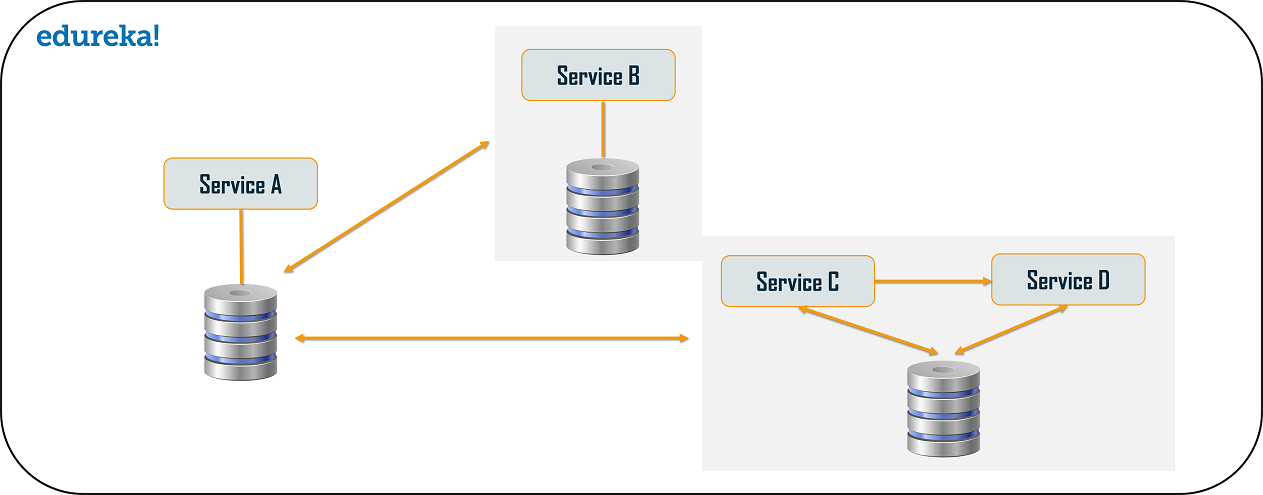
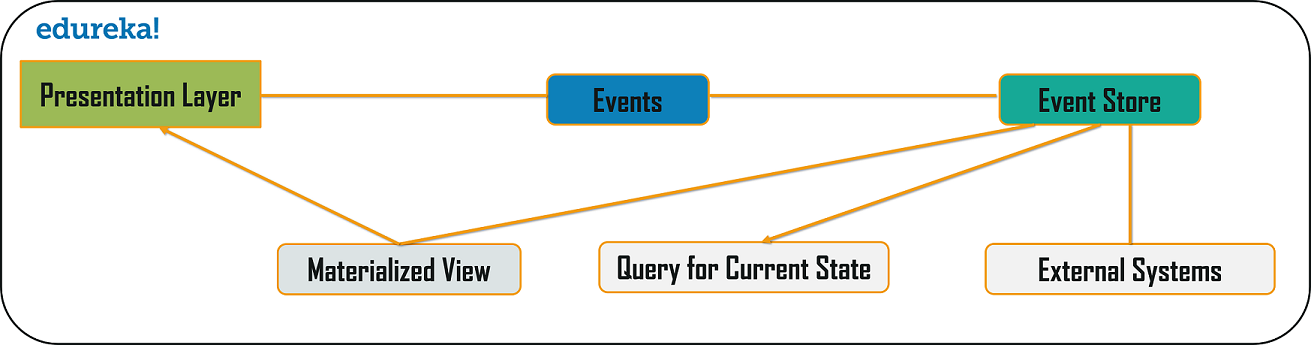
Branch Pattern
Branch microservice design pattern is a design pattern in which you can simultaneously process the requests and responses from two or more independent microservices. So, unlike the chained design pattern, the request is not passed in a sequence, but the request is passed to two or more mutually exclusive microservices chains. This design pattern extends the Aggregator design pattern and provides the flexibility to produce responses from multiple chains or single chain. For example, if you consider an e-commerce application, then you may need to retrieve data from multiple sources and this data could be a collaborated output of data from various services. So, you can use the branch pattern, to retrieve data from multiple sources.
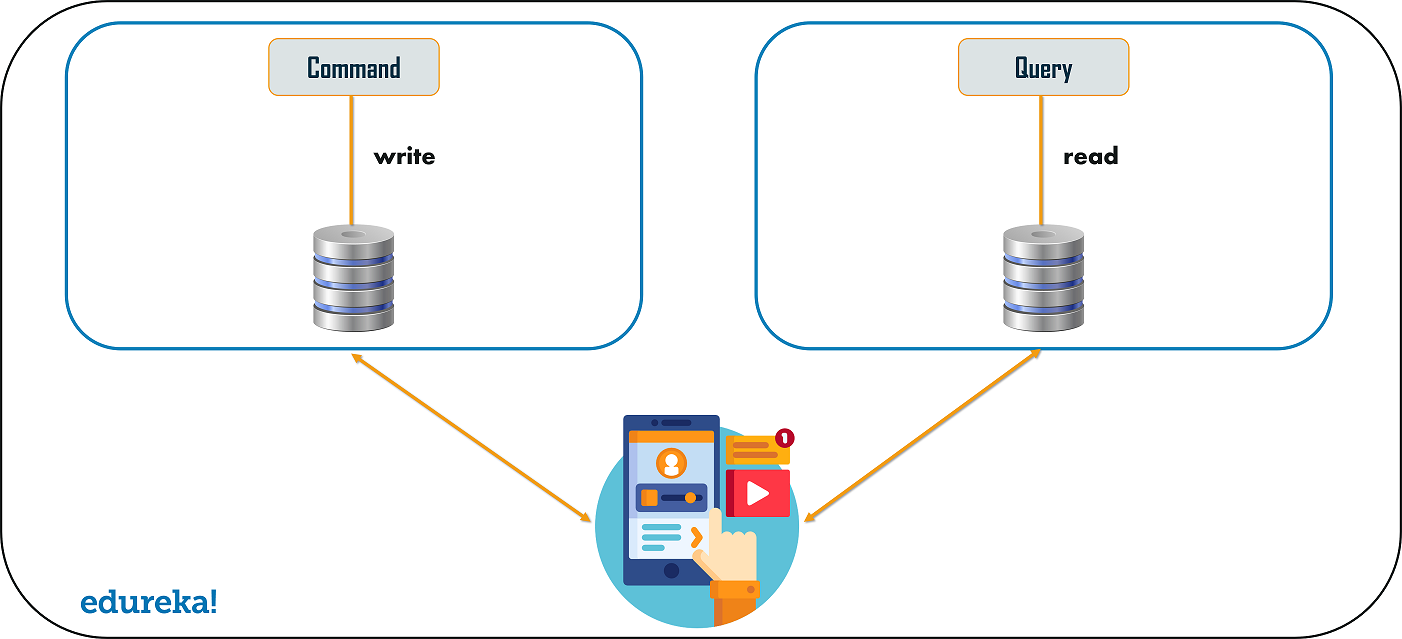
Command Query Responsibility Segregator (CQRS) Design Pattern
Every microservices design has either the database per service model or the shared database per service. But, in the database per service model, we cannot implement a query as the data access is only limited to one single database. So, in such scenario you can use the CQRS pattern. According to this pattern, the application will be divided into two parts: Command and Query. The command part will handle all the requests related to CREATE, UPDATE, DELETE while the query part will take care of the materialized views. The materialized views are updated through a sequence of events which are creating using the event source pattern discussed above.
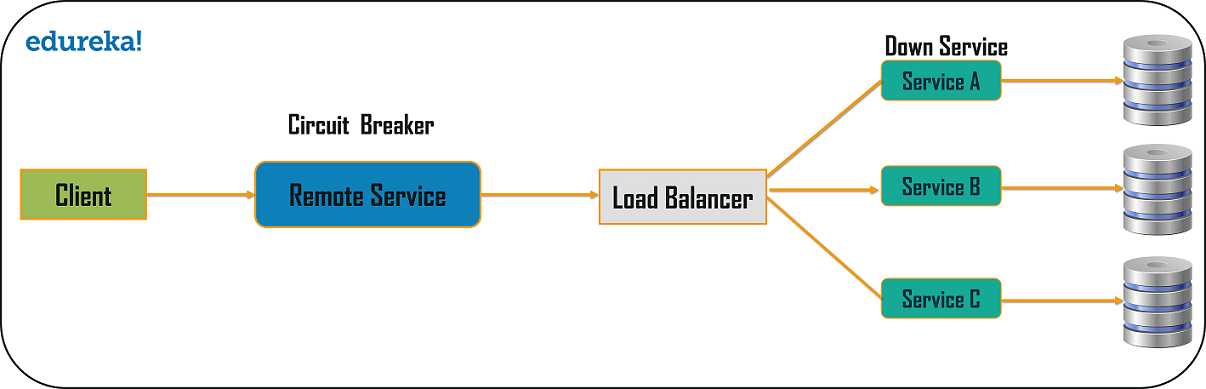
Circuit Breaker Pattern
As the name suggests, the Circuit Breaker design pattern is used to stop the process of request and response if a service is not working. So, for example, let’s say a client is sending a request to retrieve data from multiple services. But, due to some issues, one of the services is down. Now, there are mainly two problems you will face: first, since the client will not have any knowledge about a particular service being down, the request will be continuously sent to that service. The second problem is that the network resources will be exhausted with low performance and bad user experience.
So, to avoid such problems, you can use the Circuit Breaker Design Pattern. With the help of this pattern, the client will invoke a remote service via a proxy. This proxy will basically behave as a circuit barrier. So, when the number of failures crosses the threshold number, the circuit breaker trips for a particular time period. Then, all the attempts to invoke the remote service will fail in this timeout period. Once that time period is finished, the circuit breaker will allow a limited number of tests to pass through and if those requests succeed, the circuit breaker resumes back to the normal operation. Else, if there is a failure, then the time out period begins again.
Decomposition Design Pattern
Microservices are developed with an idea on developers mind to create small services, with each having their own functionality. But, breaking an application into small autonomous units has to be done logically. So, to decompose a small or big application into small services, you can use the Decomposition patterns.
With the help of this pattern, either you can decompose an application based on business capability or on based on the sub-domains. For example, if you consider an e-commerce application, then you can have separate services for orders, payment, customers, products if you decompose by business capability.
But, in the same scenario, if you design the application by decomposing the sub-domains, then you can have services for each and every class. Here, in this example, if you consider the customer as a class, then this class will be used in customer management, customer support, etc. So, to decompose, you can use the Domain-Driven Design through which the whole domain model is broken down into sub-domains. Then, each of these sub-domains will have their own specific model and scope(bounded context). Now, when a developer designs microservices, he/she will design those services around the scope or bounded context.
Though these patterns may sound feasible to you, they are not feasible for big monolithic applications. This is because of the fact that identifying sub-domains and business capabilities is not an easy task for big applications. So, the only way to decompose big monolithic applications is by following the Vine Pattern or the Strangler Pattern.
Strangler Pattern or Vine Pattern
The Strangler Pattern or the Vine Pattern is based on the analogy to a vine which basically strangles a tree that it is wrapped around. So, when this pattern is applied on the web applications, a call goes back and forth for each URI call and the services are broken down into different domains. These domains will be hosted as separate services.
According to the strangler pattern, two separate applications will live side by side in the same URI space, and one domain will be taken in to account at an instance of time. So, eventually, the new refactored application wraps around or strangles or replaces the original application until you can shut down the monolithic application
In today’s market where industries are using various software architectures and applications, it’s almost next to impossible to feel that, your data is completely secure. So, while building applications using the microservice architecture, security issues become more significant, as, individual services communicate with each other and the client. So, in this article on microservices security, I will discuss the various ways you can implement to secure your microservices in the following sequence.
What are microservices?
Microservices, aka microservice architecture, is an architectural style that structures an application as a collection of small autonomous services, modeled around a business domain. So, you can understand microservices as small individual services communicating with each other around the single business logic. If you wish to know more about microservices in-depth, then you can refer to my article.
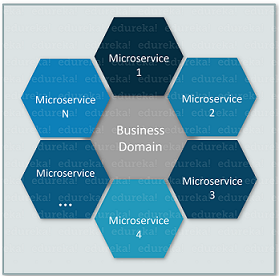
Now, often when companies shift from a monolithic architecture to microservices, they see many benefits like scalability, flexibility and short development cycles. But, at the same time, this architecture, also introduces a few complex problems.
So, next in this article on microservices security, let us understand the problems faced in a microservice architecture.
Problems faced in microservices
The problems faced in microservices are as follows:
Problem 1:
Consider a scenario, where a user needs to login to access a resource. Now, in microservices architecture, the user login details have to be saved in such a manner that, the user is not asked for verification each and every time he/she tries to access a resource. Now, this creates a problem, as the user details might not be secure and also could be accessed by the 3rd party.
Problem 2:
When a client sends a request, then the client details need to be verified and also the permissions given to the client need to be checked. So, when you use microservices, it may happen that for each and every service you have to authenticate and authorize the client. Now, to do this, developers might use the same code for each and every service. But, don’t you think relying on a specific code reduces the flexibility of microservices? Well, it definitely does. So, this is one of the major problems often faced in this architecture.
Problem 3:
The next problem which is very prominent is the security of each individual microservice. In this architecture, all the microservices communicate with each other simultaneously in addition to the 3rd party applications. So, when a client logs in from a 3rd party application, you have to make sure that the client does not get access to the data of microservices, in a way that, he/ she might exploit them.
Alright, the above-mentioned problems are not the only problems found in a microservice architecture. I would say, you could face many other problems related to security based on the application and the architecture you have. On that note, let us move forward with this article on microservices security and know the best way to reduce the challenges.
Best practices for microservices security
The best practices to improve security in microservices are as follows:
Defense in Depth Mechanism
As microservices are known to adopt any mechanism on a granular level, you can apply the Defense in Depth mechanism to make the services more secure. In layman terms, the Defense in Depth mechanism is basically a technique through which you can apply layers of security countermeasures to protect the sensitive services. So, as a developer, you just have to identify the services with the most sensitive information and then apply a number of security layers to protect them. In this way, you can make sure that any potential attacker cannot crack the security on a single go, and has to go forward and try to crack the defense mechanism of all the layers.
Also, since in a microservice architecture, you can implement different layers of security on different services, an attacker, who is successful in exploiting a particular service, might not be able to crack the defense mechanism of the other services.
Tokens and API Gateway
Often, when you open an application, you see a dialog box saying, “Accept the License Agreement and permission for cookies”. What does this message signify? Well, once you accept it, your user credentials will be stored and a session will be created. Now, the next time you go on the same page, the page will be loaded from the cache memory rather than the servers itself. Before this concept came into the picture, sessions were stored on the server-side centrally. But, this was one of the biggest barriers in horizontally scaling, the application.
Tokens
So, the solution to this problem is to use tokens, to record the user credentials. These tokens are used to easily identify the user and are stored in the form of cookies. Now, each time a client requests a web page, the request is forwarded to the server, and then, the server determines whether the user has access to the requested resource or not.
Now, the main problem is tokens where the user information is stored. So, the data of tokens need to be encrypted to avoid any exploitation from 3rd party resources. Jason Web Format or most commonly known as JWT is an open standard which defines the token format, provides libraries for various languages and also encrypts those tokens.
API Gateways
API Gateways add as an extra element to secure services through token authentication. The API Gateway acts an entry point to all the client requests and efficiently hides the microservices from the client. So, the client has no direct access to microservices and thus in that way, no client can exploit any of the services.
Distributed Tracing and Session Management
Distributed Tracing
While using microservices, you have to monitor all these services continuously. But, when you have to monitor a humongous amount of services simultaneously, then that becomes a problem. To avoid such challenges, you can use a method known as Distributed Tracing. Distributed tracing is a method to pinpoint the failures and identify the reason behind it. Not only this, but you can also identify the place at which failure is happening. So, it is very easy to track down, which microservice is facing a security issue.
Session Management
Session Management is an important parameter that you have to consider while securing microservices. Now, a session is created whenever a user comes on to an application. So, you can handle the session data in the following ways:
- You can store the session data of a single user in a specific server. But, this kind of system, completely depends on load balancing between the services and meets only horizontal scaling.
- The complete session data can be stored in a single instance. Then the data can be synchronized through the network. The only problem is that, in this method, network resources get exhausted.
- You can make sure that the user data can be obtained from the shared session storage, so as to ensure, all the services can read the same session data. But, since the data is retrieved from shared storage, you need to make sure that you have some security mechanism, to access data in a secure way.
First session and Mutual SSL
The idea of the first session is very simple. Users need to login to the application once, and then they can access all the services in the application. But, each user has to initially communicate with an authentication service. Well, this can definitely result in a lot of traffic between all the services and might be cumbersome for the developers to figure out failures in such a scenario.
Coming to Mutual SSL, applications often face traffic from users, 3rd parties and also microservices communicating with each other. But, since these services are accessed by the 3rd parties, there is always a risk of attacks. Now, the solution to such scenarios is mutual SSL or mutual authentication between microservices. With this, the data transferred between the services will be encrypted. The only problem with this method is that, when the number of microservices increase, then since each and every service will have its own TLS certificate, it will be very tough for the developers to update the certificates.
3rd party application access
All of us access applications which are 3rd party applications. The 3rd party applications use an API token generated by the user in the application to access the required resources. So, the 3rd party applications can access that particular users’ data and not other users credentials. Well, this was in respect to a single user. But what if the applications need to access data from multiple users? How do you think such a request is accommodated?
Usage of OAuth
The solution is to use OAuth. When you use OAuth, the application prompts the user to authorize the 3rd party applications, to use the required information and generate a token for it. Generally, an authorization code is used to request the token to make sure that the user’s callback URL is not stolen.
So, while mentioning the access token the client communicates with the authorization server, and this server authorizes the client to prevent others from forging the client’s identity. So, when you use Microservices with OAuth, the services act as a client in the OAuth architecture, to simplify the security issues.
Well, folks, I would not say that these are the only ways through which you can secure your services. You can secure microservices in many ways based on the architecture of the application. So, if you are someone, who is aspiring to build an application based on microservices, then remember that the security of the services is one important factor which you need to be cautious about. On that note, we come to an end to this article on microservices security. I hope you found this article informative.
Estimation:
Which estimating method is best?
Expert judgment is one of the most popular estimation techniques, as it tends to be quick and easy. This technique involves relying on the experience and gut feel of experts to estimate projects. It's most useful when you're planning a standard project that is similar to ones your team has completed before.
When should estimation happen in Scrum?
Usually, estimation should be done in 2 levels at the start of each sprint: story level and task level. For best results, product owner and team should do both together, every time, although sometimes it is acceptable for the team estimate at task level without the product owner present.
How do you estimate tasks in Scrum?
Estimate Tasks in Hours
Estimate each task as a team. Ask everyone what they think, in order to identify missed tasks, or to identify simpler solutions. Ideally task estimates should be no more than 1 day. If an estimate is much larger than this, the requirements should be broken down further so the tasks are smaller.
What is used to estimate tasks in Agile?
Traditional software teams give estimates in a time format: days, weeks, months. Many agile teams, however, have transitioned to story points. Story points are units of measure for expressing an estimate of the overall effort required to fully implement a product backlog item or any other piece of work.
Microservice Questions
How do you decide what should be a microservice?
If a module needs to have a completely independent lifecycle (meaning the code commit to production flow), then it should be a microservice. It should have its own code repository, CI/CD pipeline, and so on. Smaller scope makes it far easier to test a microservice.
What is microservice technology?
How do you select a specific technology for microservice development
Microservices - also known as the microservice architecture - is an architectural style that structures an application as a collection of services that are. Highly maintainable and testable. Loosely coupled. Independently deployable. Organized around business capabilities.
What are best practices for designing the microservices ?
Best Practices for Designing a Microservices Architecture
Create a Separate Data Store for Each Microservice
Do not use the same backend data store across microservices. You want the team for each microservice to choose the database that best suits the service. Moreover, with a single data store it’s too easy for microservices written by different teams to share database structures, perhaps in the name of reducing duplication of work. You end up with the situation where if one team updates a database structure, other services that also use that structure have to be changed too.
Breaking apart the data can make data management more complicated, because the separate storage systems can more easily get out sync or become inconsistent, and foreign keys can change unexpectedly. You need to add a tool that performs master data management (MDM) by operating in the background to find and fix inconsistencies. For example, it might examine every database that stores subscriber IDs, to verify that the same IDs exist in all of them (there aren’t missing or extra IDs in any one database). You can write your own tool or buy one. Many commercial relational database management systems (RDBMSs) do these kinds of checks, but they usually impose too many requirements for coupling, and so don’t scale.
Keep Code at a Similar Level of Maturity
Keep all code in a microservice at a similar level of maturity and stability. In other words, if you need to add or rewrite some of the code in a deployed microservice that’s working well, the best approach is usually to create a new microservice for the new or changed code, leaving the existing microservice in place. [Editor – This is sometimes referred to as the immutable infrastructure principle.] This way you can iteratively deploy and test the new code until it is bug free and maximally efficient, without risking failure or performance degradation in the existing microservice. Once the new microservice is as stable as the original, you can merge them back together if they really perform a single function together, or if there are other efficiencies from combining them. However, in Cockcroft’s experience it is much more common to realize you should split up a microservice because it’s gotten too big.
Do a Separate Build for Each Microservice
Do a separate build for each microservice, so that it can pull in component files from the repository at the revision levels appropriate to it. This sometimes leads to the situation where various microservices pull in a similar set of files, but at different revision levels. That can make it more difficult to clean up your codebase by decommissioning old file versions (because you have to verify more carefully that a revision is no longer being used), but that’s an acceptable trade‑off for how easy it is to add new files as you build new microservices. The asymmetry is intentional: you want introducing a new microservice, file, or function to be easy, not dangerous.
Deploy in Containers
Deploying microservices in containers is important because it means you just need just one tool to deploy everything. As long as the microservice is in a container, the tool knows how to deploy it. It doesn’t matter what the container is. That said, Docker seems very quickly to have become the de facto standard for containers.
Treat Servers as Stateless
Treat servers, particularly those that run customer‑facing code, as interchangeable members of a group. They all perform the same functions, so you don’t need to be concerned about them individually. Your only concern is that there are enough of them to produce the amount of work you need, and you can use autoscaling to adjust the numbers up and down. If one stops working, it’s automatically replaced by another one. Avoid “snowflake” systems in which you depend on individual servers to perform specialized functions.
Cockcroft’s analogy is that you want to think of servers like cattle, not pets. If you have a machine in production that performs a specialized function, and you know it by name, and everyone gets sad when it goes down, it’s a pet. Instead you should think of your servers like a herd of cows. What you care about is how many gallons of milk you get. If one day you notice you’re getting less milk than usual, you find out which cows aren’t producing well and replace them.

Comments
Post a Comment